在线配资炒股开户
热点资讯
- 配资网站是真的吗 陈艺文不再回避!被多位记者诽谤、造谣性取向,回怼:真给你脸了
- 衡水股票配资 吐鲁番迎来极热天气 火焰山景区部分区域地表温度达81℃
- 十倍杠杆 5月财政收支出炉:增值税同比由负转正 卖地收入降幅继续扩大
- 正规的线上配资平台 俄罗斯宣布反制美国
- 股票融资配资 蔚能与中豫产投、隆兴集团、领诚基金四方达成战略合作
- 配资网炒股 华宏科技:9月30日获融资买入611.87万元,占当日流入资金比例7.48%
- 炒股杠杆配资申请 惠伦晶体:2024年半年度归属于上市公司股东的净利润2581356.79元
- 炒股杠杆有哪些app 苏文电能(300982)12月12日主力资金净买入1334.41万元
- 股票配资网站合法吗 前五月全国政府性基金预算收入16638亿元,同比下降10.8%
- 168股票配资线上站 大厂开工率降至约60%,光伏硅片全面涨价
- 发布日期:2024-10-10 22:20 点击次数:62

残暴的欢愉股票的杠杆怎么用,终将以残暴结束。
当盛宴开启之时,没人想到,大模型的淘汰赛,会来的如此之快。
火药味首先表现在创投市场。PitchBook 最新报告披露,相比 2023 年一季度,全球 2024 年一季度大模型融资额,从 216.9 亿美元增长到了 258.7 亿美元,但涉及的交易数量,却从 1909 笔下滑至 1545 笔——产业格局正迅速向强者收拢。
大厂的价格战,则彻底关上了后来者进入的大门。5 月 6 日,幻方量化率先打响降价「大战」第一枪,随后将字节、百度、阿里、京东、腾讯、智谱,全部拖下水,轻量级模型每千 tokens,价格内卷「从分到厘」。不到一个月时间里,后来者的感慨就从跟不上,变成了跟不起。
秋风扫落叶式的前后夹击,使得短短两年不到,技术尚未走到尽头,产业侧就完成了从萌芽到江山初定的格局演练。
然而,胜利者同时也被拖入了另一场更漫长的消耗战中。三朵阴云始终判断在大模型行业的头顶挥之不去:
以目前的技术迭代速度,GPU 还够吗?究竟是模型参数的膨胀速度更快,还是账上现金的消耗更快?十项全能、没有幻觉的通用大模型,真存在吗?
当问题变得无解,过度的追求模型的技术领先,也就成为了一种诅咒。
当淘汰赛暂时画上休止符,行业开始决定换一种活法。
中原(工商铺)工商部董事刘重兴表示,香港逾百幢工厦并分作四大区域作工厦表现分析,2024年第2季指标工厦买卖成交录得约88宗,较第一季的57宗增约54%,除东九龙区环比上季录得跌幅外,港岛、西九龙及新界的买卖宗数均大幅上升,当中西九龙区买卖成交量占比最多,季内录得约39宗买卖成交,环比上季增近七成,平均呎价亦有上升,由第一季约4525元,微升至第2季的4834元,幅度约6.8%,另外新界区亦录得17宗成交,环比上季大增约1.8倍。
此外,天风国际分析师郭明錤近日发文表示,GB200 NVL36和NVL72耗电量太大,大部分数据中心短期内无法部署;GB200 NVL36的算力优势无庸置疑,但也面临许多前所未见的设计与生产挑战,故担忧能否确保如期大量出货。
01 一当暴力不再有奇迹,大模型正陷入技术的诅咒
绝对的大参数,或许并不是大模型落地的唯一解法。
这句话,正逐渐成为大模型产业的共识。·
其中,参数做大路上的第一个隘口,正是这场盛宴中最大的获胜者——英伟达。
最近,一份出自 Meta 研究报告显示:其最新的 Llama 3 405B 参数模型在 16384 个 Nvidia H100 GPU 组成的集群上训练时,54 天内经历了 419 次意外,训练期间平均每三个小时就发生一次故障。与此同时,每次的单个 GPU 故障,都会中断整个训练过程,导致训练重新启动。
简单翻译来说,当前的大模型参数量,已经接近硬件所能支撑的极限。即便有无穷无尽的 GPU,也不再能解决大模型训练中的算力模型。如果朝着扩大参数的路上继续狂奔,那么训练的过程,将变成西西弗斯推石头式的无限重来。
硬件增大了大模型扩张的难度,细分场景中,智能程度不再与参数量成正比,则从实用角度为这场暴力的欢愉画上了一个大大的问号。
大模型的场景正不断变得复杂化和专业化、碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,几乎异想天开。
一个国内大模型厂商最爱使用的技术比较维度是:与 GPT4 比诗词赏析和弱智吧段子,几乎无一例外,无论模型大小,开源模型套壳与否,国产大模型全数吊打「世界第一」。甚至,在最基础的鲁迅与周树人的关系这样的文学常识题上,最优秀的大模型,也比不过一个最传统的搜索引擎。
回归到实际应用中,商业化的不可能三角,彻底为参数信徒们兜头浇来一盆凉水。
在实际应用中,除了模型的智能程度,产品经理们还需考虑速度与成本两大因素。通常 来说,在问答中 1 秒内的响应速度,99% 的准确率,以及能打平成本的商业模式,会是一个大模型生存的必要条件。
但使用大参数路线推高智能,往往也就意味着智能程度越高,产品的应答速度越慢,成本越高,反之亦然。
如果一味由着参数无限制扩张,AI 也将无可避免的变成一场资本的战争,但扩张的代价,却远远超过历史上的任何一场同等阶段的商业比拼……对已经踩下油门的玩家来说,只有把筹码加到对手跟不起的水平,才能让自己输得不会太惨。
于是,面对隐约可及的天花板,行业的课题开始转向:如果万能模型不存在,暴力无奇迹,行业要去往哪里?
02 大模型的 T 型车时刻:CoE or MoE?
当一个大模型同时完成通用+专业的可行性被堵死,多模型联合分工成为了行业第二阶段的主旋律。
1913 年, 福特公司创造性的将屠宰线思路引入汽车产业,开发出了世界上第一条流水线。汽车生产,自此从老师傅手工组装,迈入工业化进程,一辆汽车的生产时间压缩近 60 倍,售价降低也足足一倍有余。汽车制造,自此迈入一个新的时代。
同样的 T 型车时刻,也发生在大模型产业。
以最典型的场景翻译来说,一个好的翻译,应达到信达雅三层境界。但在大模型的世界里,传统翻译大模型只能做到信,达与雅,则依靠写作大模型才能完成。
但关于何如进行多模型分工,行业则分成了旗帜鲜明的合纵派与连横派。
合纵派的技术思路是 MoE。
所谓 MoE(Mixture-of-Experts),翻译成中文就是混合专家模型,将多个细分领域的专家模型组合成一个超级模型。早在 2022 年,Google 就提出了 MoE 大模型 Switch Transformer,使得其凭借 1571B 的参数量,也能 在预训练任务上显示出比 T5-XXL(11B)模型更高的样本效率(更准确,且计算成本没有显著提升)。
不仅如此,美国知名骇客 George Hotz 与 PyTorch 的创建者 Soumith Chintala 也先后表示,GPT4 也是由 8 个 220B 参数量的 MoE 模型组成的 1760B 参数大模型,算不严格意义的「一个」万亿模型。
然而,这种 8 合一的思路,也导致了 MoE 的设计与每次升级迭代都需要花费巨大的资源。类似日常爬山,爬一座 8848m 高的珠穆朗玛峰的难度,远不是爬 8 次海拔 1108 米的雁荡山耗费体力的加和。因此,有能力参与的,往往都是 8 项全能其具备绝对领先优势的 AI 技术龙头。
于是,随着 MoE 逐渐成为寡头的游戏,一种新的技术思路走上台前——连横派的 CoE。
CoE(Collaboration-of-Experts),即专家协同模型。通俗来说,一个入口同时接入多家模型,而入口会在模型分析之前,增加一个意图识别环节,然后才进行任务派解,决定任务是由哪款模型起作用,或者哪几款模型打配合。相对于 MoE,CoE 最大的优势是,各个专家模型之间可以彼此协同工作,但不存在绑定关系。
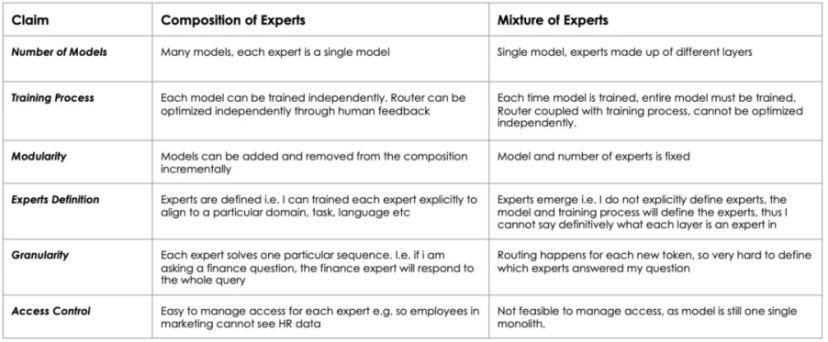
相比 MoE,CoE 的每个专家模型之间有更多的协同,更精准的分工,并且更灵活、更专业细分。这一思路,相比 MoE,具有更高的效率,和更低的API接口和 Token 使用成本。
那么,MoE 与 CoE 哪种路线会更占上风?
03 另一种解题思路:什么决定了用户的智能体验?
当周鸿祎一袭红衣转型 AI 教父时,360 内部,关于如何 CoE 与 MoE 路线的论证,也在最近一年多时间里反复上演。
如果走 MoE,360 多年技术的积累,足以支撑打完这场仗。
而走 CoE,就意味着与更多的大模型厂家同分一杯羹。
「三个臭皮匠,顶一个诸葛亮」给了 360 集团副总裁梁志辉启发,要将宝压在 CoE 上:
一家企业,哪怕做到 Open AI 式「8 项全能」,依然不免存在短板。但如果将最优秀的大模型企业能力,通过 CoE 能力,则意味着优势互补与真正十八项全能的实现。
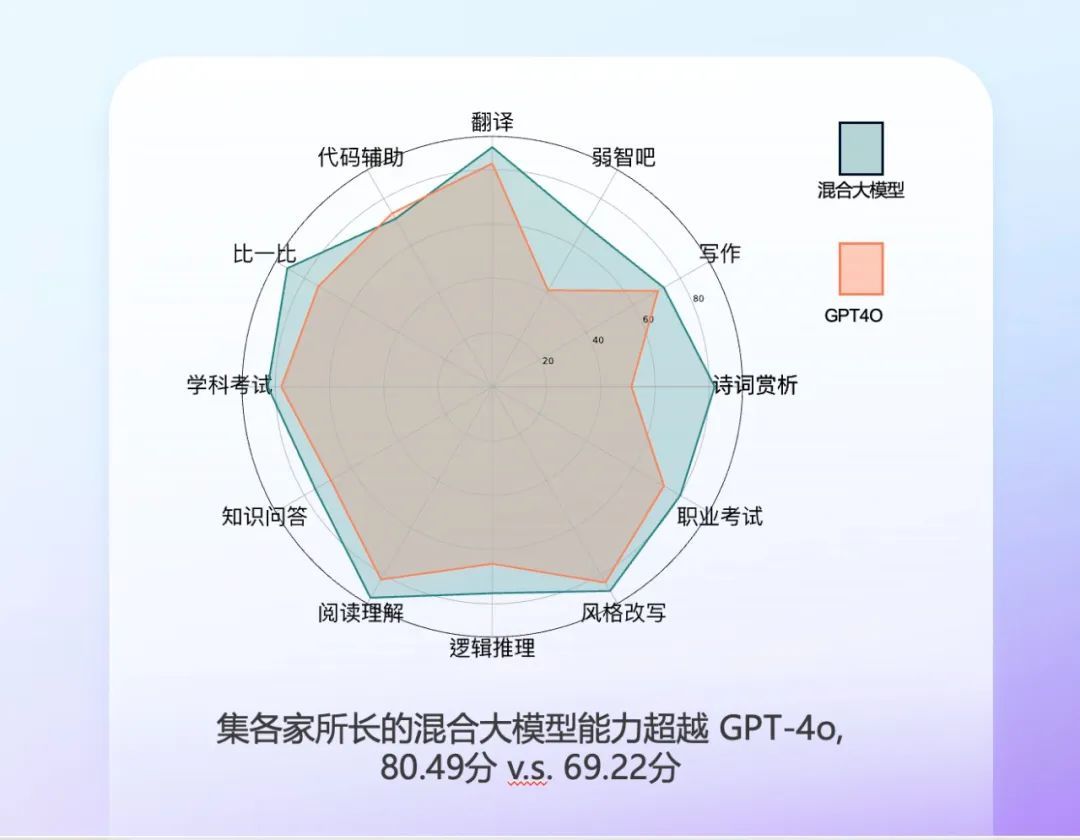
测评结果显示,基于 360 CoE AI 能力的 AI 助手 Beta 版,在引入 360 智脑在内的 16 家国内最强大模型集各家所长后,已在 11 个单项能力测试指标上超越 GPT-4o。
与此同时,即使将底层大模型能力「外包」,360 依然能在 CoE 的浪潮中,找到自己的独家定位。
从产品层面看,360 CoE 产品 AI 助手可以被分成两个部分:其中,语料积累与算法技术,主要依靠的是 360 智脑在内的 16 家国产大模型的接入,类似分工不同的特种兵;而360 则充当指挥官的角色,通过意图识别模型,来实现对于用户意图更加精准的理解;通过任务分解和调度模型,实现了对于众多专家模型网络(100+LLM)、千亿规模知识中枢和 200+第三方工具的智能调度,进而实现比 MoE 更高的灵活性和效率。

其背后的逻辑在于,当下阶段,决定用户侧所能感知到的模型智能程度的几大要素排序中,需求理解>语料积累>算法技术。
其中,语料大于算法的逻辑,主要体现在细分场景。一个不太恰当的比喻是,一个初高中搜题软件在解决数学和物理问题上,都能秒杀 GPT-4o。
关于如何理解需求理解的重要性,梁志辉用 360 最新发布的 CoE AI 工具 AI 助手举了个例子,比如,关于「比如起床第一件事是做什么」的问题,大部分用户期待的或许是一个养生型的答案,而一个热爱弱智吧问答的用户,期待的答案却是睁眼。
在这种实际场景下,不同于客观的评分与打榜,用户对模型智能程度的感知,是主观的。
而做好用户的主观意图判断,则需要对用户历史行为的积累。如果玩家是像 360 这样有搜索引擎、浏览器数据积累的玩家,则意味着对用户问题的拆解可以做到更加精准,更进一步,通过历史数据,就能判定用户的检索意图,一步给出最合适的答案。
确认了 CoE 与 360 的定位后,一个新的问题又随即出现在眼前,基于以上功能设计,360 基于 CoE 架构的AI 助手,究竟是作为自家浏览器、搜索引擎、办公产品中的附加功能,还是作为一个独立应用存在。
最终路线定在两相结合,前者提供更多场景,后者创造更多可能。
8 月 1 日,ISC.AI2024 第十二届互联网安全大会·人工智能峰会开幕上,360 创始人周鸿祎正式发布「AI 助手」。在保留独立的网址入口基础上,AI 助手也将其全面内置到 360 国民级入口产品,用户不需要安装插件,即可获取 AI 体验,与此同时,用户使用 AI 助手功能时,还可以对模型一键切换,16 家国内主流大模型,「哪家最强用哪家」。

AI 助手的使用示范
选择将AI助手内置到成熟应用的最直接原因是用户体验。
基础的技术突破,是抡起锤子对一个钉子猛敲;而落地与商业,则是无数个名叫用户体验、场景连续、技术领先、产品生态的齿轮相嵌合,组成的庞大系统性工程。AI 的使用需求,往往伴随场景产生,比如网页的翻译,文章的扩写。如果将这些功能放在不同页面、插件甚至 APP 之间来回跳转,则意味着使用流程的断点与门槛。
发布会上,周鸿祎对此做出了进一步解释:
「大模型不是产品,而是能力,能力固然很重要,但能力一定要跟场景相结合,才能真正的产生价值。」「大模型像今天电器时代的电动机,这东西可大可小、可强可弱、可快可慢,就看怎么用。比如把电动机拿到工厂传送带,就变成流水线,如果加上四个轮子、底盘、外壳,就能得到一辆汽车。发动机在过程中发挥着重要的作用,但是用户并不需要直接发动机,用户需要发动机提供的能力和很多部件相结合。」
用户体验之外,AI助手绑定浏览器的另一个优势则在于成本。
用户侧成本而言,传统的模式中,用户获得更精准的回答,往往只能选择使用更大参数也更贵的大模型这一条路。而通过 AI 助手,基于 CoE 架构的意图识别、任务路由模型,问题可以被精准分发匹配到最合适的模型回答,成本也随之降低。
而在产业生态角度,AI 助手被集成到安全卫士、浏览器中,则意味着对大模型几乎零成本的流量导入。一般来说,大模型的成本,主要由训练时的研发与硬件采购支出,以及推理时的网络、算力消耗决定,与传统的互联网模式类似,前期的研发成本,会随着后期用户规模的扩大,而在单用户访问成本上被摊得越薄。
360 旗下产品获得了更多AI能力的加持,用户获得了更精准更顺滑的使用体验,大模型厂商获得了免费的流量与继续坐在牌桌上的资格。AI 助手从页面交互上看,或许只是一个新增功能的改变,但于大模型而言,却是一场一鱼三吃,产品、技术、用户三赢的新商业模式的开端。
这也解释了,为何不久前以阿里钉钉的号召力,争取到的是「七个葫芦娃」的入驻;而这次 360 发布「AI 助手」,却首发就是 16 家,几乎是把国内主流大模型厂商「一网打尽」。或许只有一家一家写下来,才能感受到这个阵营以及这种号召力的强大:
大厂:百度、字节跳动、腾讯、阿里巴巴、华为;
五小虎:智谱 AI、月之暗面、MiniMax、百川智能、零一万物;
垂类头部:商汤科技、科大讯飞、好未来、幻方量化、面壁智能。
04 尾声
从大模型改变世界,到原子弹变茶叶蛋;从模型为王到合纵连横,从 MoE 到 CoE……短短两年时间,大模型就走完了从初代产品一鸣惊人,到产业淘汰赛,再到商业化的三步走。
而大模型产业的进化速度,也正如其漫无边际膨胀的参数,快速将对手挑落马下,同时快速将自己送到了每一个新兴赛道的终极之问面前:
要生存,还是要伟大。
历史已经替参赛者做出回答——如果生存不能保证股票的杠杆怎么用,伟大只会成为对手成功路上的垫脚石。
- 股票的杠杆怎么用 173只ETF获融资净买入 华安黄金ETF居首2025-02-18